花了好一番功夫,把我們的面板整理好之後,
接著就來做個好用的「詞語代換功能」吧。
平常我們無論是在閱讀機器翻譯的文字,
或是修改機器翻譯的譯文,
經常都會遇到某些奇怪的用詞反覆出現,
每次看到都想把它直接換掉!
就憑著這股看不慣的怨念,
我們或許一時之間很有動力、很有耐心去把它們一個一個換掉,
但這種動力是很珍貴的,
反覆替換文字的機械性操作,只會損耗這種珍貴的動力,
到後來很快你就會發現,算了算了,
一個一個換太累,
姑且就接受它吧,反正看得懂就好了。
於是你就這樣,接受了那些奇怪的用字遣詞,
但在潛移默化之間,有一天你終究會察覺,
自己的用字遣詞似乎受到了影響。
你會發現自己說出來的話、寫出來的文字,
竟然開始使用那些很奇怪的用語了。
其實語言是活的,
越來越多人這樣那樣用,語言就會往這樣那樣靠過去。
上一代人看不慣下一代的注音文、火星文,
其實也就是這樣來的。
如果有一天,這種奇怪的文字逐漸變成主流,
使用所謂優美文字的人,反而變成了老古板,
那實在太讓人遺憾了呀!
當然,語言文字保持一定的活力,也不是壞事,
尤其現在有 Google 機器翻譯這樣的東西存在,
更降低了各種不同語言彼此交流的門檻。
不同語言之間互相劇烈影響,也是意料中事。
但優美道地的文字,在這場交流中相當弱勢,
根本沒什麼機會影響這些變化。
除非,我們給她更多的機會,參與到這場變革之中。
這就是我認為,「最好的翻譯依然是人」的緣故。
我們今天就來建立一個簡單的界面,
把那些讓人看不慣的奇怪用語,毫不留情的換掉吧!
首先,來看一下我們目前的面板架構:
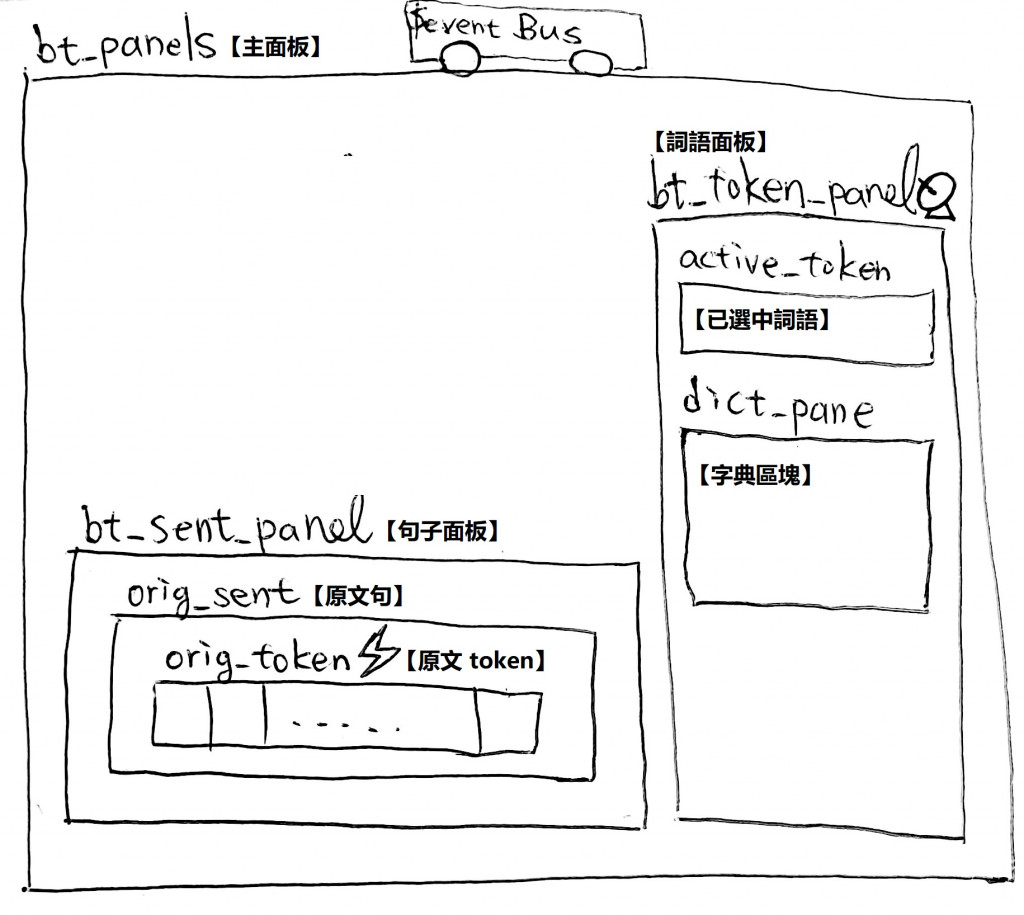
我們打算做下面這幾件事:
saved_terms = {
term#1: [ // 採用列表結構,可以讓同一個 term 保存多組翻譯替換方式
{ // 以 token/term 為索引
ot_text: aaa, // 原文
mt_text: bbb, // 機譯:機器翻譯
tt_text: ccc, // 人譯:真人翻譯
},
{第二種解釋方式...},
...
]
...
}
這裡之所以採用 term 而不用 token,主要是希望將來能用 term 涵蓋 token(單詞)與 phrase(片語)的意思
更新後的架構如下:
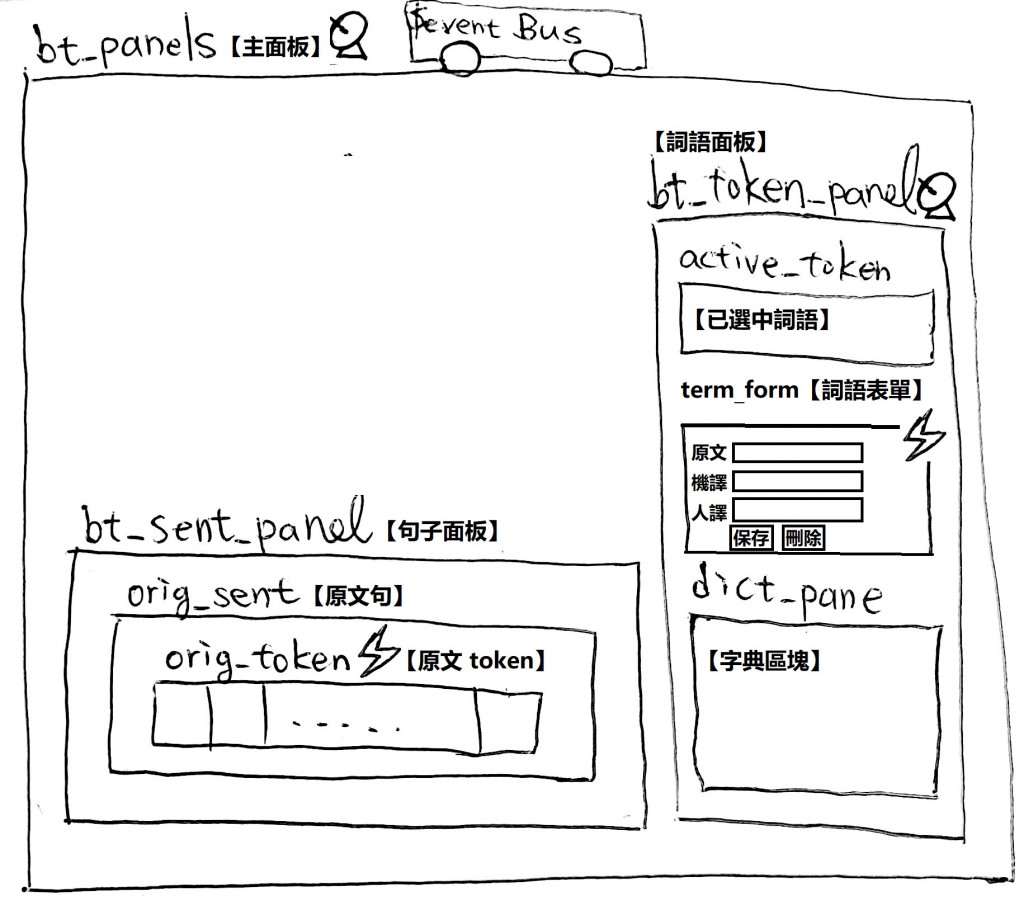
程式碼的部分,有興趣請自行參見 Github 囉。
完成以上的相應程式碼修改之後,
我們只要在下方的【句子面板】點擊某個單字,
所點擊的詞語就會出現在右方【詞語面板】裡的【詞語表單】中,
而且其中【原文】的欄位已經填好資料,
我們只要再填入【機譯】(機器翻譯)【人譯】(真人翻譯)的資料,
然後點擊下方的保存即可(也可刪除某組特定的記錄)。
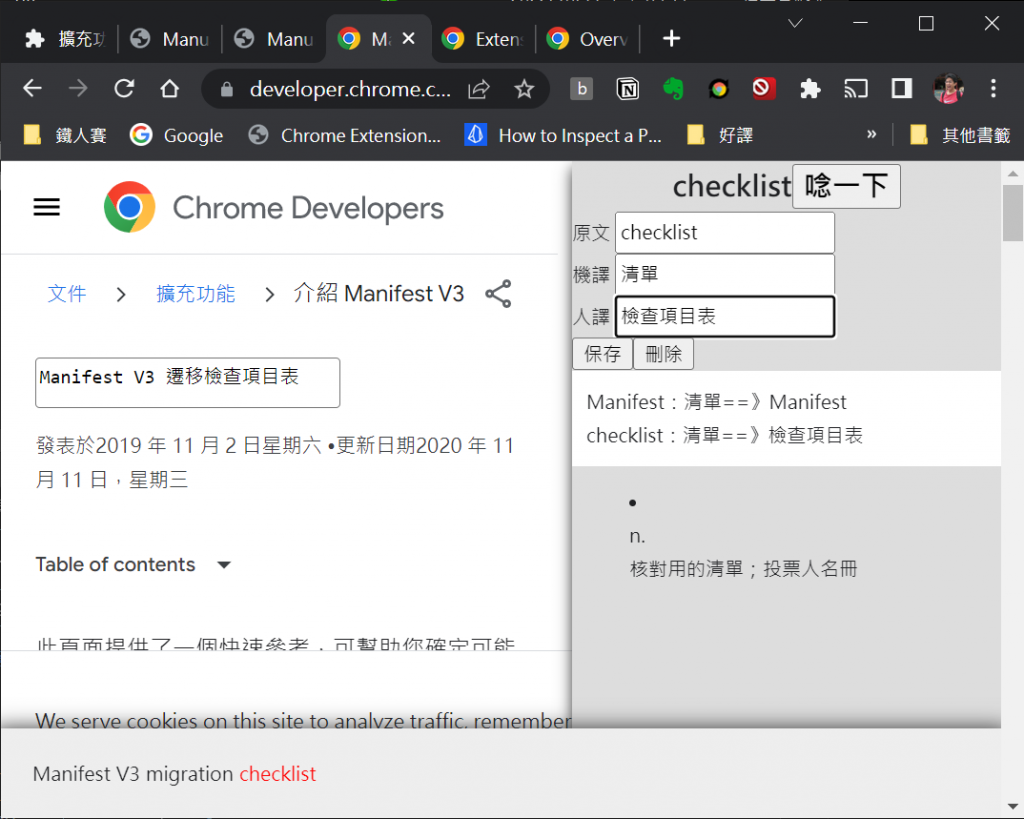
保存好【原文/機譯/人譯】的資料,
隨後在進行翻譯時,如果原文句中出現同樣的原文詞語,
系統就會檢查譯文中是否出現【機譯】的文字,
如果有的話,就會自動替換成【人譯】的文字了。
舉例來說,
假設我們保存了一組資料如下:
這樣一來,在編輯翻譯時,
如果原文句中出現 memory,而譯文中出現了【內存】的文字,
我們的系統就會自動把【內存】替換成【記憶體】了。
這樣的替換方式,參考了更多的【線索】(原文),
所以就不會發生「海內存知己」被替換成「海記憶體知己」的情況了。
有了這種更精準的替換方式,
我們當然也可以更有信心,直接進行全文替換的動作。
不過,全文替換畢竟是很暴力的做法,
比較保險的做法,還是希望譯者能逐一檢查內容。
目前我們只會在譯者編輯每個句子時,自動進行相應的替換。
如果想要進一步進行全文替換,也不是不行,
但同時間應搭配其他做法,
例如陳列出所有將被替換的句子內容,以便於快速檢查,
或是針對替換過的句子,標示特殊的翻譯狀態,提醒譯者特別留意等等。
以上這些更進階的做法,都是可以進一步發展的功能。
將來有機會的話,也許我們可以再陸續推展,
手很癢實在忍不住的同學,當然也可以自己嘗試看看囉 ^_^


 iThome鐵人賽
iThome鐵人賽